Speech Synthesis in Chromium
I saw this cool project the other day, a web extension that helps you learn Japanese by showing a new word and its definition on every new tab. I wanted to apply the concept to otherother languages like French though—luckily the extension JapaneseTab is open source. I was cleaning and familiarizing myself with the code base, pruning features and UI elements I didn't like, until I noticed that no matter how hard or how many times I clicked the small play audio button on the right side of the hiragana to pronounce it, no sound would come out.
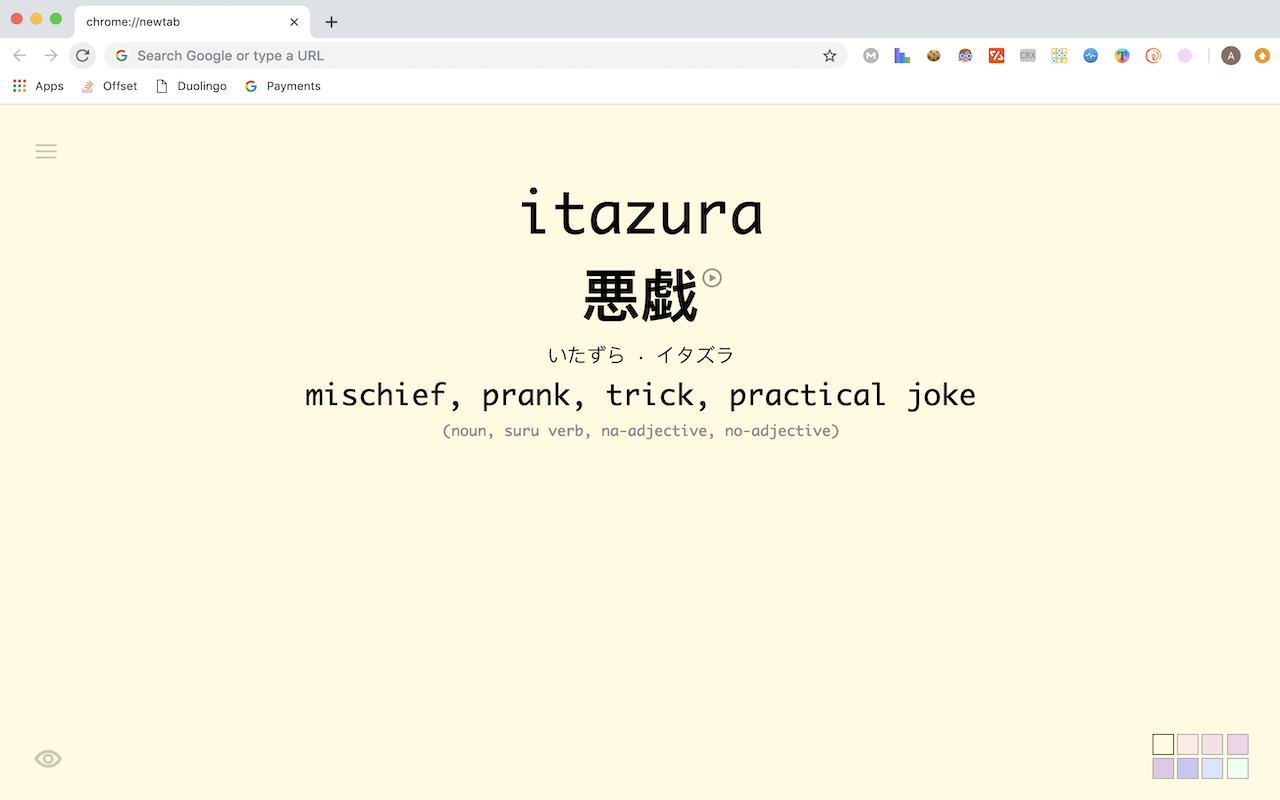
I ruled out idiotic possibilities like muted audio and dug further. JapaneseTab uses the Web Speech API for speech synthesis. In fact, press ctrl+shift+j right now and a panel should appear. Paste the following code into that panel, and a robotic voice should tell you about the Web Speech API:
window.speechSynthesis.speak(new SpeechSynthesisUtterance("The Web Speech API, an API supported by all major browsers, allows for easy speech recognition and synthesis."));No sound came out for me though, when running the code in the console panel. I suspected that Chromium didn't have this API builtin. I searched online for anyone else who might've had this problem with Chromium and found an answer by Luis Rebelo who claimed that I needed to use a certain flag and install certain packages. I did so,
$ sudo pacman -S espeak-ng speech-dispatcher
$ pkill chromium
$ chromium --enable-speech-dispatcherAnd I saw this really intimating warning message when I launched Chromium again, stating that, "You are using an unsupported command-line flag: --enable-speech-dispatcher. Stability and security will suffer." No new bad thing has happened yet that I can attribute to this flag though—hopefully it stays this way.
By the way, the speech-dispatcher package allows one to access TTS on the CLI with a consistent interface, despite different backends, in various languages:
$ spd-say -l fr bonjour
$ spd-say -l cmn-latn-pinyin 你好
$ spd-say -l ja こんにちはAnd just one last thing before I end off. I wrote some Rust code (for practice) to generate definitions and example sentences for the most frequent French words using an LLM. More specifically, it runs Mistral-7b locally through Ollama, which is a project I submitted a PR to once to fix a tiny readline library inconsistency, but I digress.
use serde::Deserialize;
use std::io::prelude::*;
#[derive(Deserialize)]
struct Response {
response: String,
}
#[tokio::main]
async fn main() -> Result<(), reqwest::Error> {
let client = reqwest::Client::new();
let reader = std::io::BufReader::new(
std::fs::File::open("french.txt").unwrap());
for line in reader.lines() {
let line = line.unwrap();
let word = line.split_whitespace().last().unwrap();
if word.len() > 2 {
let prompt =
format!("
Me: déranger
You: to bother; Ne dérange pas mes livres, s’il te plaît.
Me: paris
You: Paris; Cela fait huit ans qu’elle habite à Paris.
Me: vêtements
You: clothing; Les vêtements sont essentiels pour se protéger du froid.
Me: prophète
You: prophet; Nul n’est prophète en son pays.
Me: {}
You:
", word)
.trim()
.replace("\n", "\\n");
let response = client
.post("http://localhost:11434/api/generate")
.body(
format!(r#"{{
"model": "mistral:instruct",
"prompt": "{}",
"options": {{
"stop": ["Me:", "You:"],
"temperature": 0.2,
"top_k": 12,
"top_p": 0.5,
"num_thread": 3
}},
"raw": true,
"stream": false
}}"#, prompt)
.to_string(),
)
.send().await?
.json::<Response>().await?;
let response: Vec<&str> = response.response.split("; ").collect();
println!(
"[{word:?}, {:?}, {:?}],",
response[0].trim(),
response[1].trim()
);
}
}
Ok(())
}