Experimenting with Huffman Coding
Huffman coding generates a tree from text and uses this tree to optimally and losslessly compress the text. Here is the tree generated from the text "beekeepers keep bees":
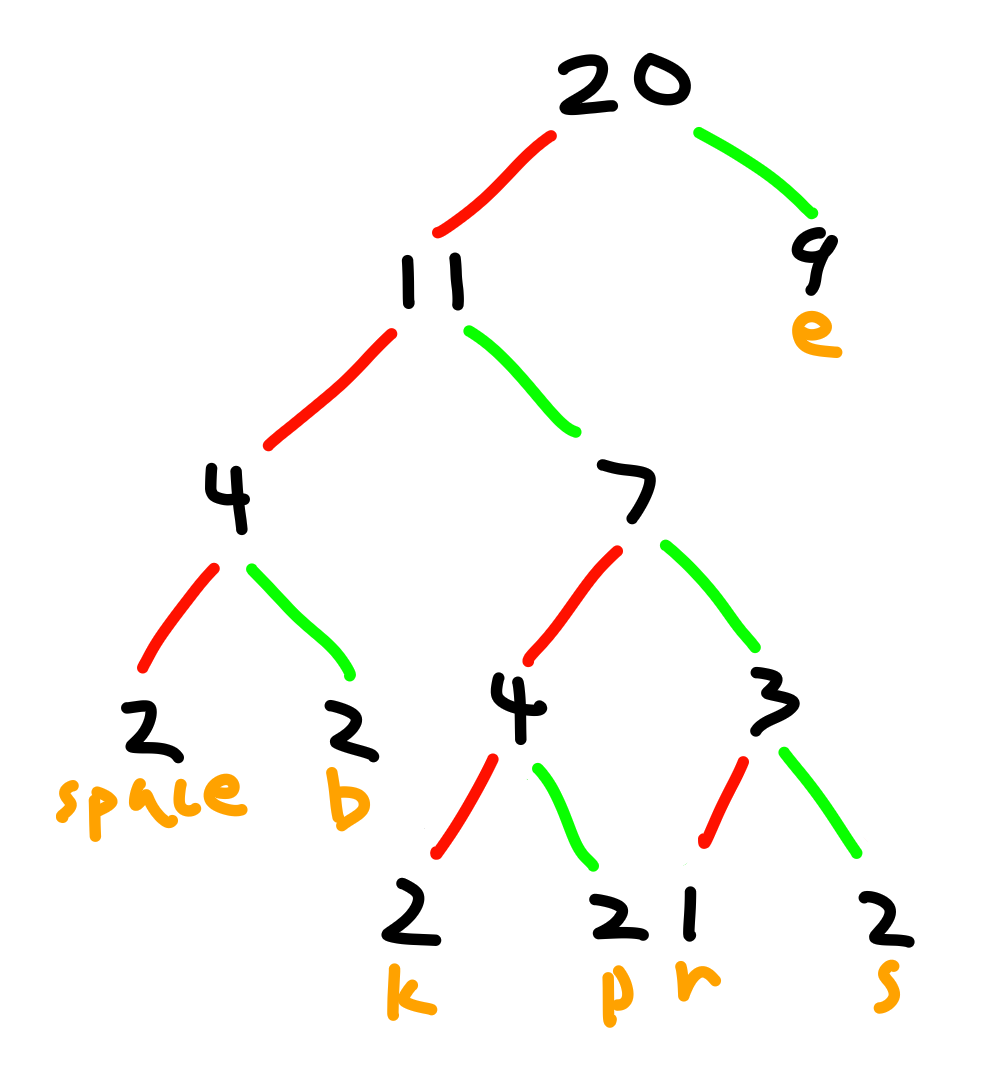
You can see the letter "E" occurs in the phrase frequently, so it's near the top. To compress text, follow the branches (colored lines) down to each letter. Each time you take a right, write down 1; each time you take a left, write down 0. For example, using the tree, the word "bees" would be encoded as 001110111. This is smaller than 1100010110010111001011110011, which is how it's represented uncompressed.
To generate the tree from text, create a sorted list of the letters by their frequencies. Repeatedly take the two elements with the lowest frequencies, make them the children of a parent (whose frequency is the combined frequency of its children), and then insert this back into the list. Continue until only one element is left, which is your tree.
Here's a Python script that does this:
import bisect
import pickle
import sys
from collections import Counter
from functools import cached_property
class Tree:
def __init__(self, lhs: (chr,int), rhs=None) -> None:
self.lhs = lhs
self.rhs = rhs
if rhs is None:
self.rhs = ('', 0)
@cached_property
def is_leaf(self) -> bool:
return self.rhs == ('', 0)
@cached_property
def freq(self) -> int:
if self.is_leaf:
return self.lhs[1]
return self.lhs.freq + self.rhs.freq
@cached_property
def letters(self) -> str:
if self.is_leaf:
return self.lhs[0]
return self.lhs.letters + self.rhs.letters
if __name__ == '__main__':
if len(sys.argv) != 3:
print('''
usage: python3 huffman.py [compress|uncompress] [file]
Compresses data from stdin.
'''.strip())
sys.exit(1)
match sys.argv[1]:
case 'compress':
txt = sys.stdin.read()
freqs = [
Tree(f)
for f in Counter(txt).most_common()
]
while len(freqs) > 1:
bisect.insort(
freqs, Tree(freqs[-1], freqs[-2]),
# bisect.insort doesn't work for lists in
# descending order, this is a fix.
key=lambda x: -1*x.freq
)
del freqs[-2:]
tree = freqs[0]
def compress(tree: Tree, txt: str) -> int:
copy = tree
data = [1]
for c in txt:
while not tree.is_leaf:
if c in tree.lhs.letters:
data.append(0)
tree = tree.lhs
else:
data.append(1)
tree = tree.rhs
tree = copy
return int(''.join(str(b) for b in data), 2)
pickle.dump(
(tree, compress(tree, txt)),
open(sys.argv[2], 'wb')
)
case 'uncompress':
copy, data = pickle.load(open(sys.argv[2], 'rb'))
data = [int(b) for b in list(bin(data)[3:])]
txt = []
i = 0
while i<len(data):
tree = copy
while not tree.is_leaf:
if data[i]:
tree = tree.rhs
else:
tree = tree.lhs
i += 1
txt.append(tree.lhs[0])
print(''.join(txt), end='')In the code, I could've also used a priority queue, instead of inserting into a sorted list. To use it:
$ echo 'beekeepers keep bees' | python3 huffman.py compress out.hm
$ python3 huffman.py uncompress out.hm
beekeepers keep bees
$ wc -c out.hm # means file is 521 bytes
521 out.hmWait, our input text is 21 bytes, but our output is 26 times larger? This is because we have to store the tree in addition to the compressed text, so Huffman coding actually enlarges short texts. Also, I'm using pickle, which is not the most space-efficient method.
The program is slow, taking about 10 seconds to compress and uncompress the The Complete Works of William Shakespeare (which I downloaded from Gutenberg in plaintext--its 172420 lines and 5.5 megabytes) to 60% of its original size:
$ time cat shakespeare.txt | python3 huffman.py compress out.hm
real 0m9.672s
user 0m8.611s
sys 0m0.962s
$ time python3 huffman.py uncompress out.hm >/dev/null
real 0m10.856s
user 0m10.480s
sys 0m0.196s
$ du -sh shakespeare.txt out.hm
5.5M shakespeare.txt
3.3M out.hmCompare this with GNU Tar, which takes 0.4 seconds to compress and 0.1 seconds to uncompress, reducing the file to 37% percent of its original size.
I've made the script run faster by adding @cached_property and using other techniques. Originally, I used a series of bit operations on integers with masks and such to compress and uncompress, but doing so is significantly slower than what I'm currently doing. I can't simply pickle the list because that results in a file much larger than the original file.