Artificial Intelligence for Dummies
I haven't written anything in a few weeks, since I'm busy researching NTT and how someone can efficiently solve large Vandermonde systems over arbitrary prime fields in $O(n \log^2 n)$ using Lagrange interpolation. I might write about those topics in the future.
For now, in this post, I'll try to explain artificial intelligence to a non-technical audience—that is, for the laity who aren't conversant with computing concepts, like my dad. I'm not very familiar with the field of AI myself, so if you spot any factual inaccuracies or find a specific topic confusing, give me an email.
There's been a lot of talk on artificial intelligence recently, with companies and startups using the term indiscriminately to market their products. I'll begin by giving a quick overview of what AI is, some common terminology, a simple example of machine learning, then explain at a high-level about how modern systems like ChatGPT and Stable Diffusion work.
An Overview
Artificial intelligence (AI) is when computers try to act like humans and do things that require intelligence, like understanding language or making decisions. AI is a very general concept and really depends on someone's personal preconception of what human intelligence is.
Machine learning (ML) is a popular type of AI where computers specifically learn from examples using computer algorithms. With machine learning, computers look at a lot of data and find patterns in it. They then use those patterns to make predictions or decisions about new information they haven't seen before.
Machine learning is split into 3 broad categories:
- Supervised learning - The computer is given labeled example data and learns to make predictions or decisions based on that.
- Unsupervised learning - The computer finds patterns in data without being given any labels or examples ahead of time.
- Reinforcement learning - The computer learns by trying different actions and getting feedback on whether those actions were good or bad.
An Example: Linear Regression
Let's say we have collected data on the weights and heights of a group of people. We can plot each person's height on the $x$-axis and their corresponding weight on the $y$-axis, creating a graph.
If we are given the height of a new person, how can we use our original data to predict their weight? Well, we can try to draw a line that best fits all of the data points we have. Then, we can determine the line's $y$ value at the $x$ value equal to the new person's height to predict their weight.
For example, with the graph below, we can guess that a person with height 67 will probably have a weight of around 141, if we follow the red line.
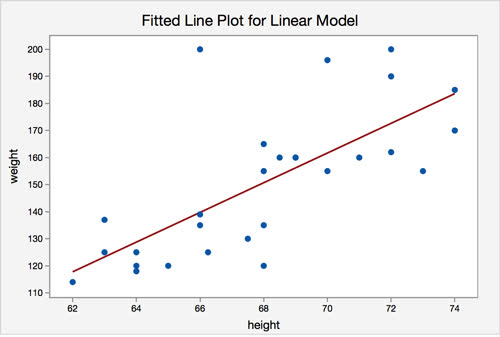
This method of predicting future values by finding the line of best fit is called linear regression. It's an example of a machine learning algorithm. The resulting line of best fit that linear regression finds is called the model, and creating this line from the data using linear regression is called training the model.
In our math classes we learn that lines can be expressed with the equation $y = mx + b$, where their are 2 variables $m$ and $b$ that control the placement of the line. Linear regression attempts to find the values for $m$ and $b$ that minimizes the distance between each data point. Therefore, the line of best fit that we find with linear regression can be completely described by two variables. We call these variables that describe the model its parameters.
Deep Learning
Most of the exciting new AI technologies like AI chatbots, art generators, and voice cloning technologies work using deep learning, a specific type of machine learning that has become very popular and promising in recent years. It's a way of training computers using a structure inspired by the human brain called neural networks to learn from data.
The "deep" in deep learning refers to the fact that these neural networks have multiple layers. In a deep learning model, the data goes through many different layers of these interconnected nodes, kind of like how information is processed through the neurons in the human brain. In practice, neural networks are represented in computers as numbers in the form of a matrix.
How Does ChatGPT Work
ChatGPT is an AI chatbot trained by the organization OpenAI. ChatGPT is a deep learning model. Go experiment and play around with ChatGPT, it's fun to observe its behaviour and limitations.
To be specific, ChatGPT is a large language model (LLM). LLMs are machine learning models that generate human language. They are trained by learning from a huge amount of text data from books, websites, and social media conversations.
Imagine you're trying to guess what word comes next in a sentence. If you've read a lot of sentences before, you can probably make a pretty good guess about the next word. That's how LLMs like ChatGPT work—they've learned patterns from language from reading so much text that they can predict the most likely next word in a sentence.
Let's look at an example of how we might use an LLM to generate text:
- I have a string of words, called the context. I start with the word "I" in the context. I feed the context into ChatGPT. ChatGPT tells me that it thinks the word "am" is the most likely to be next. If you look at billions of words, the word "am" often follows the word "I", so this is a very logical choice by ChatGPT. I append "am" onto the context.
- The context is now "I am." I again feed the context into ChatGPT, and ChatGPT tells me that it thinks that "feeling" is the most likely next word to follow. I append the word "feeling" onto the context.
- The context is now "I am feeling." I feed the context, again, back into ChatGPT. ChatGPT tells me that it thinks "tired" is the most likely next word. I append the word "tired" onto the context.
- Now, we have the full sentence "I am feeling tired" written by ChatGPT word-by-word!
Essentially, LLMs are tools that tell us the probabilities of the next word given a sequence of previous words.
When you type out a text to someone on your smartphone, above the keyboard is a bar that suggests to you possible next words or phrases that you might want to write. LLMs can be thought of as these really advanced word suggesters like the one on your smartphone when you text—imagine just randomly accepting suggestions your smartphone gives you, you'll get some vaguely human-like text.
The linear regression example I gave had 2 parameters, $m$ and $b$. ChatGPT has 175 billion parameters—an astronomical amount! Computers usually store numbers in 32 bits, so you would need 700 gigabytes to store ChatGPT. That's around the size of your computer's entire storage capacity.
LLMs like ChatGPT need to see hundreds of billions of words before they can become proficient in predicting language. Therefore, training LLMs require a lot of computing power from powerful, specialized devices called GPUs. ChatGPT would've taken around 2 million years to train on your laptop, but luckily ChatGPT can be trained in just a month using 1000 of those GPUs.
This is the reason why Nvidia's market cap is the third highest in the world as of April 1st. Nvidia is the only company right now that sells these high-quality GPUs which are required for training these large AI models. The compute to train ChatGPT cost OpenAI 4 million dollars!
A question you may have is that if ChatGPT only predicts the next word, then how is it that we can have a pleasant conversation with it? The answer is that we write a dialogue, like this:
You are ChatGPT, an AI assistant. This is a dialogue between a human and you. Human: Hello, who are you? ChatGPT: I am ChatGPT, an AI assistant. Human: What is the capital of Canada? ChatGPT: The captial of Canada is Ottawa. Human: What is the tallest mountain on Earth? ChatGPT:
We leave out ChatGPT's response, so when it predicts that the next few words in the dialogue are something like "The tallest mountain is Mount Everest" we can interpret that as its response to the human user. If the human user types something else, we can append ChatGPT's previous response and the human user's new request together onto the dialogue and feed this new dialogue into ChatGPT again to let it respond. Remember: All ChatGPT does is predict the next word.
Large language models were trained by other organizations before OpenAI and the technical groundwork was set by Google, but one of OpenAI's key innovations and the primary reason for their success (along with training a really big LLM) was to present the LLM in an easy to understand chatbot interface, making it more accessible for the general public to use and admire.
I will provide more detail here on how LLMs operate, for those interested. If these details are confusing, skip them; they aren't essential.
- Machine learning models can only work with numbers. So these LLMs work with tokens, which are lists of numbers called vectors. These tokens might correspond with words, but in LLMs currently they correspond more like to syllables. Play around with ChatGPT's tokenizer to get an idea of how LLMs see the world. Tokenisation is very important, since it represents what the LLM can see. Tokenisation also leads to a lot of the problems with LLMs, like the fact that they can't spell well—because they see only syllables, not individual characters.
How Do AI Art Generators Work
AIs that generate art like the models Stable Diffusion and DALL·E use deep learning too but in a different way from LLMs. You can try out a version of Stable Diffusion on Replicate for free. These art generators are trained by learning from a huge amount of image data scraped from the Internet.
In real life, we take pictures with our smartphones. Sometimes the pictures come out a little noisy or blurry, perhaps because of bad lighting conditions when it's nighttime. Luckily, we can train a deep learning model to remove the noise in the image we take using our smartphones.
Let's say this noise-remover model was trained on images of beautiful landscapes, so it's especially good at cleaning the noise from landscape images.
Now, what if we give this noise-remover model an image of purely random noise? An image of complete static, resembling the black and white static screen we might see on a television. We get an image with slightly less noise.
The key idea of AI art generators is to apply this noise-remover model multiple times to an image, starting with completely static noise. Look at the animation below.
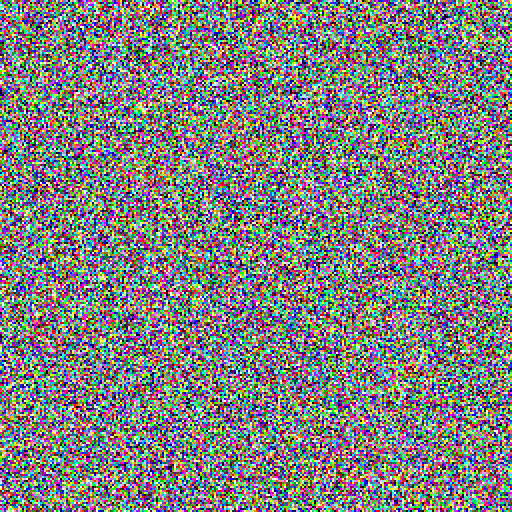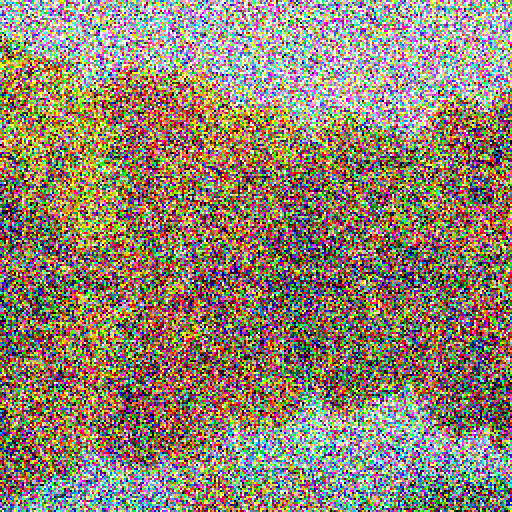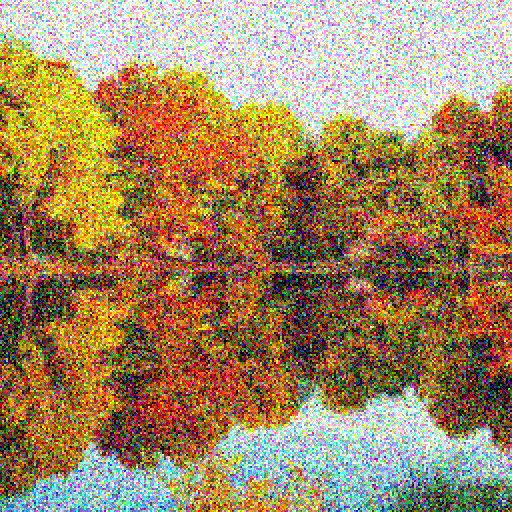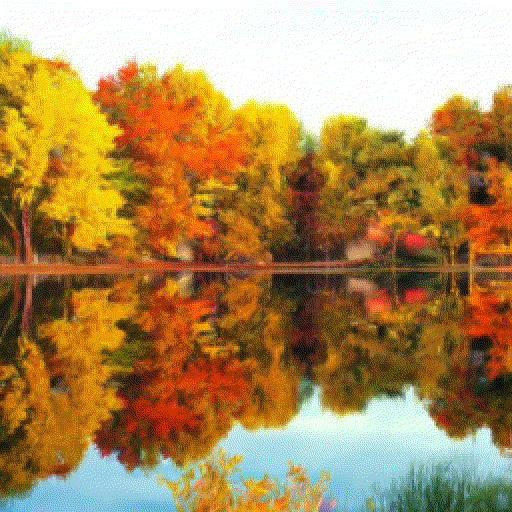
The animation starts with an image composed of purely static noise.
- First, we feed the completely noisy image into the noise-remover model. It removes a little of the noise.
- We then feed this new image with a little bit of the noise removed back into the noise-remover model. It removes a little more of the noise.
- We continue this process and gradually start to see a clean, crisp image. Eventually, all the noise is removed and we are left with the image of a beautiful landscape.
AI art generators are called diffusion models, which mean they "draw" art by successively removing noise from an image.
These diffusion models are also much smaller than capable LLMs like ChatGPT, boasting only a few billion parameters. Who would've thought it would be harder to accurately teach a model to write then to draw?
I will provide more detail here on how AI art models operate, for those interested. If these details are confusing, skip them; they aren't essential.
- In particular, Stable Diffusion is a latent diffusion model which means in actuality it performs the denoising diffusion process on a 32x32 image. They then upscale this image to 512x512 later on. This is to save computing power, as diffusion on the full resolution 512x512 is expensive.
- It seems that all future AI art generators will use DiT (diffusion transformer) as does Stable Diffusion 3 and Sora (probably) do. If you look at Stable Diffusion 3, it has much better prompt coherency—meaning it more closely draws what the user specifics—then previous models and possess the impressive ability to write long sequences of text, which older models notoriously struggled with. I don't understand at all how DiTs work; the diagrams in the Stable Diffusion 3 paper look like "human instrumentality" said one Twitter user (it's a Neon Genesis Evangelion reference and means the diagrams are really complicated).
Conclusion
I enjoy exploring and understanding how these AI systems work, even though my knowledge in this domain is somewhat superficial. I think that current deep learning models are quite magical.
This post on AI is my first time writing such a long post and one geared towards an audience without my own background knowledge. I hope I wrote this article in a way that is understandable enough without sacrificing any essential detail.
ChatGPT was trained on 300 billion tokens and consumed 314,000 exaflops, as explained in the paper. Assuming a consumer laptop CPU can sustain 5 gigaflops—which is optimistic—then it would've required 1.991 million years to train.
Image credits:
- Linear regression plot is from Penn State university.
- Stable diffusion GIF is from Aditya Ramesh's blog post and was originally created by Alex Nichol.